

If you are coding in Python, you aren’t just using a language; you are tapping into a massive ecosystem of tools and Top Python Libraries. The true power of Python doesn’t come from its syntax, but from its libraries — especially the Top Python Libraries that make data science, web development, automation, and AI so accessible.
Whether you are into Data Science, Web Development, Machine Learning, or just automating boring tasks, there is a library that has already done the heavy lifting for you.
In this guide, we break down the top Python Libraries you need to know in 2024, explaining exactly what functionalities make them indispensable.
1. Pandas
Category: Data Manipulation & Analysis
Pandas is a Python library that makes working with data easy. It’s one of the Top Python Libraries for data analysis and manipulation. If you have ever used Excel, then Pandas is like having Excel inside Python — but much faster and more powerful. As part of the broader ecosystem of Top Python Libraries, Pandas helps developers clean, transform, and analyze data efficiently.
It helps you:
- Read data
- Clean data
- Fix mistakes in data
- Analyze patterns
- Create new columns
- Prepare data for machine learning
All of this can be done with very little code.
Key Functionalities:
- DataFrame Object: Pandas stores data in a structure called a DataFrame, which looks like rows and columns of a spreadsheet.
Code snippets that demonstrate common Pandas features :
import streamlit as st
import pandas as pd
st.title("Pandas Data Cleaning & Transformation – Full Demo")
# ---------------------------------------------------------
# 1. Load Data
# ---------------------------------------------------------
st.header("Load Data")
try:
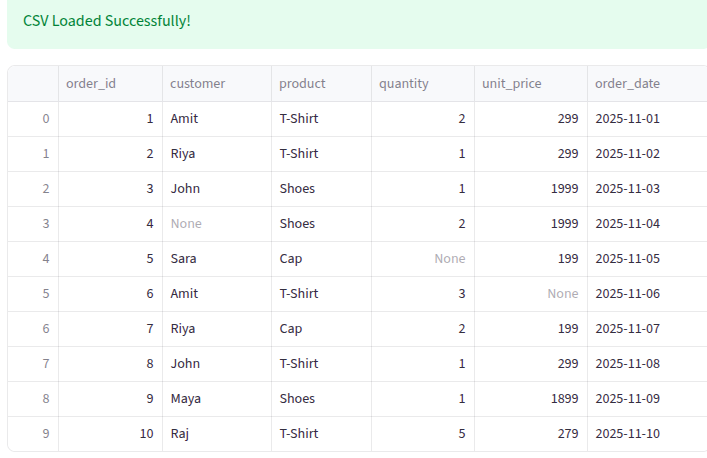
df = pd.read_csv("csvfile/pandas_demo_sales.csv")
st.success("CSV Loaded Successfully!")
except FileNotFoundError:
st.error("❌ File not found: csvfile/pandas_demo_sales.csv")
st.stop()
st.dataframe(df)
# ---------------------------------------------------------
# 2. Inspect Data
# ---------------------------------------------------------
st.header("Inspect Data")
st.subheader("Shape of DataFrame")
st.write(df.shape)
st.subheader("Column Data Types")
st.write(df.dtypes)
st.subheader("Missing Values Per Column")
st.write(df.isnull().sum())
st.subheader("Preview of Data (Head)")
st.dataframe(df.head())
# ---------------------------------------------------------
# 3. Cleaning
# ---------------------------------------------------------
st.header("Data Cleaning Steps")
df_clean = df.copy()
df_clean = df_clean.rename(columns={"unit_price": "unit_price_inr"})
df_clean["order_date"] = pd.to_datetime(df_clean["order_date"])
df_clean["quantity"] = df_clean["quantity"].fillna(1).astype(int)
median_price = df_clean["unit_price_inr"].median(skipna=True)
df_clean["unit_price_inr"] = df_clean["unit_price_inr"].fillna(median_price)
df_clean["customer"] = df_clean["customer"].fillna("Unknown")
st.subheader("Median Price Used to Fill Missing Values")
st.write(median_price)
st.subheader("Cleaned DataFrame")
st.dataframe(df_clean)
# ---------------------------------------------------------
# 4. Transformations
# ---------------------------------------------------------
st.header("Data Transformations")
df_clean["total_price"] = df_clean["quantity"] * df_clean["unit_price_inr"]
df_clean["order_month"] = df_clean["order_date"].dt.to_period("M").astype(str)
df_clean["product_cat"] = df_clean["product"].astype("category")
df_clean["product_code"] = df_clean["product_cat"].cat.codes
st.subheader("Transformed DataFrame")
st.dataframe(df_clean)
# ---------------------------------------------------------
# 5. Aggregations
# ---------------------------------------------------------
st.header("Aggregation Results")
sales_by_product = df_clean.groupby("product").agg(
total_quantity=("quantity", "sum"),
total_revenue=("total_price", "sum"),
orders=("order_id", "count")
).reset_index().sort_values("total_revenue", ascending=False)
monthly_sales = df_clean.groupby("order_month").agg(
monthly_revenue=("total_price", "sum"),
monthly_orders=("order_id", "count")
).reset_index().sort_values("order_month")
st.subheader("Sales by Product")
st.dataframe(sales_by_product)
st.subheader("Monthly Sales Summary")
st.dataframe(monthly_sales)
st.success("All steps completed successfully!")Output for the tabular format:
2. NumPy
Category: Scientific Computing
Python is one of the most popular programming languages for data science, machine learning, and scientific computing. Among the Top Python Libraries, NumPy stands out when it comes to handling numbers and performing calculations efficiently. The built-in Python lists sometimes fall short — that’s where NumPy comes in.
Why NumPy is Important
Imagine you need to process thousands or millions of numbers. Using plain Python lists would be slow and memory-heavy, especially for complex operations like matrix multiplication or statistical calculations. That’s why tools like NumPy are considered part of the Top Python Libraries for high-performance numerical computing.
NumPy solves these problems by:
- Optimized storage: It stores data in contiguous memory blocks, which makes computations faster.
- Vectorized operations: You can perform calculations on entire arrays without writing loops.
- Integration with other libraries: Pandas, Matplotlib, SciPy, and even machine learning libraries like TensorFlow rely on NumPy arrays.
Key Functionalities:
- N-dimensional Arrays: Offers the ndarray, a fast and flexible container for large datasets.
- Mathematical Operations: Performs complex linear algebra, Fourier transforms, and random number capabilities.
- Broadcasting: Allows you to perform arithmetic operations on arrays of different shapes.
- Integration: seamless integration with C/C++ and Fortran code.
Code snippets that demonstrate common NumPy features :
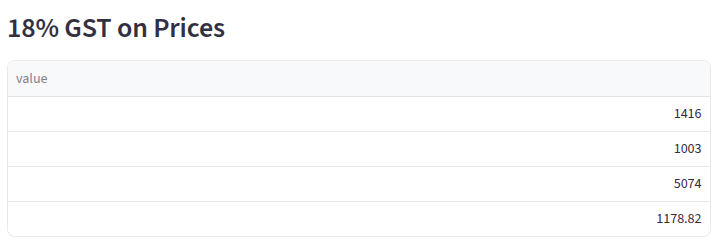
import numpy as np
prices = np.array([1200, 850, 4300, 999])
tax = np.array([0.18]) # 18% GST
st.subheader("18% GST on Prices")
final_amount = prices + (prices * tax)
st.dataframe(final_amount)Output:
3. Requests
Category: Web & HTTP
requests is a Python library used to send HTTP/1.1 requests using simple Python methods like:
GETPOSTPUTDELETEPATCHHEAD
It abstracts the complexity of Python’s built-in urllib and gives you an elegant, human-friendly API.
Key Functionalities:
- API Interaction: Sends HTTP requests (GET, POST, PUT, DELETE) to web servers effortlessly.
- Parameter Handling: automatically adds query strings and form-encodes your POST data.
- Authentication: Handles various authentication types (Basic, Digest, OAuth) smoothly.
- Session Objects: Persists parameters (like cookies) across requests.
Example: Fetching data from an API
import requests
url = "https://jsonplaceholder.typicode.com/posts/1"
response = requests.get(url)
print("Status Code:", response.status_code)
print("Response JSON:", response.json())Output:
Status Code: 200
Response JSON: {
'userId': 1,
'id': 1,
'title': 'sunt aut facere repellat provident occaecati excepturi optio reprehenderit',
'body': 'quia et suscipit\nsuscipit recusandae consequuntur...'
}4. Matplotlib
Category: Data Visualization
Data visualization plays a crucial role in data analysis, machine learning, automation, and decision-making. Among the Top Python Libraries for this purpose, the most widely used and powerful library for plotting and visual analysis is Matplotlib. Whether you are working with financial data, machine learning results, statistics, or business dashboards, Matplotlib — a key member of the Top Python Libraries ecosystem — allows you to create compelling visualizations with just a few lines of code.
In this blog post, we will explore Matplotlib, understand its key features, and walk through practical code examples you can use immediately.
What is Matplotlib?
Matplotlib is a comprehensive Python library for creating static, interactive, and animated visualizations. It supports many types of charts, such as:
- Line charts
- Bar charts
- Histograms
- Pie charts
- Scatter plots
- Heatmaps
- Subplots & grids
It is built on NumPy arrays and integrates seamlessly with Pandas, SciPy, Seaborn, and Jupyter Notebook.
To install:
pip install matplotlibCode snippets that demonstrate Line charts:
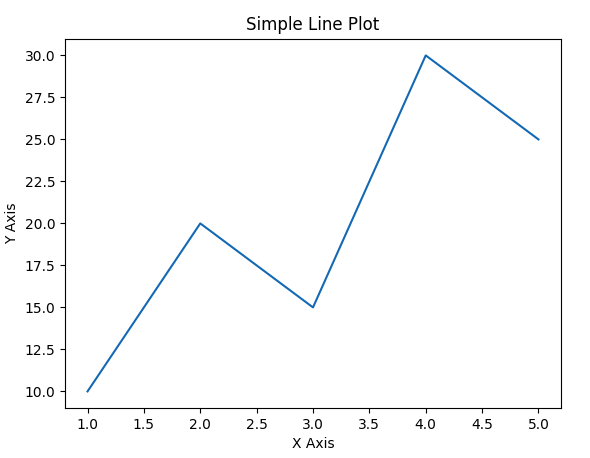
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [10, 20, 15, 30, 25]
plt.plot(x, y)
plt.title("Simple Line Plot")
plt.xlabel("X Axis")
plt.ylabel("Y Axis")
# To show on UI uncomment it
#plt.show()
# Save output instead of showing
plt.savefig("output_plot.png") # save in project folder
plt.close()Output:
5. Scikit-Learn
Category: Machine Learning (Classical)
If you are stepping into the world of machine learning, one name you will hear again and again is Scikit-Learn. It is one of the most popular and easy-to-use libraries for building, training, and evaluating machine learning models, and it’s often listed among the Top Python Libraries for ML. Whether you want to predict house prices, classify emails as spam or not spam, or cluster customers based on their behaviour, Scikit-Learn — a core part of the Top Python Libraries ecosystem — gives you all the tools in a clean and simple interfac
What makes Scikit-Learn special is its design philosophy: simplicity, consistency, and modularity. Among the Top Python Libraries for machine learning, almost every algorithm in the library follows the same pattern — create a model, fit it with training data, and then make predictions. This consistent interface, shared by many of the Top Python Libraries, makes the learning curve smooth even for beginners.
Why is Scikit-Learn so widely used?
Here are some reasons why developers and data scientists love this library:
1. Large collection of algorithms
Scikit-Learn includes almost every traditional machine learning algorithm you can think of — Linear Regression, Logistic Regression, Decision Trees, Random Forest, K-Means, Naive Bayes, SVM, and many more. It’s one of the Top Python Libraries for implementing these models efficiently. Because Scikit-Learn is part of the broader ecosystem of the Top Python Libraries used in data science and ML, it integrates smoothly with tools like NumPy and Pandas.
2. Easy data preprocessing
Real-world data is rarely clean. The library provides tools for:
- handling missing values
- encoding categorical data
- scaling features
- splitting data into train/test
3. Consistent model workflow
Every model uses the same steps:
model = Algorithm()model.fit(X_train, y_train)predictions = model.predict(X_test)
This uniform approach saves a lot of time.
4. Works well with Pandas and NumPy
Scikit-Learn is designed to integrate smoothly with other tools in the ecosystem of Top Python Libraries, like Pandas, NumPy, and Matplotlib. Together, these Top Python Libraries make it easy to build end-to-end data science and machine learning workflows in Python.
Key Functionalities:
- Classification: Identifying which category an object belongs to (e.g., Spam detection).
- Regression: Predicting a continuous-valued attribute associated with an object (e.g., Stock prices).
- Clustering: Automatic grouping of similar objects into sets (e.g., Customer segmentation).
- Preprocessing: Features for normalization, scaling, and encoding data before feeding it to models.
Real-Life Example: Predicting House Prices
Let’s walk through a simple machine learning example: predicting house prices using Linear Regression — a classic use case supported by some of the Top Python Libraries in data science. This example shows how the Top Python Libraries make building real machine learning models both simple and efficient.
We will assume a dataset that contains:
- Area (sq. ft.)
- Number of bedrooms
- House price
Code snippets that demonstrate Line charts:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Sample dataset
data = {
"area_sqft": [800, 1200, 1500, 1800, 2000, 2200],
"bedrooms": [2, 3, 3, 4, 4, 5],
"price_lakh": [45, 70, 85, 110, 130, 150]
}
df = pd.DataFrame(data)
# Features (X) and Target (y)
X = df[["area_sqft", "bedrooms"]]
y = df["price_lakh"]
# Train/Test Split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
pred = model.predict(X_test)
# Evaluate the model
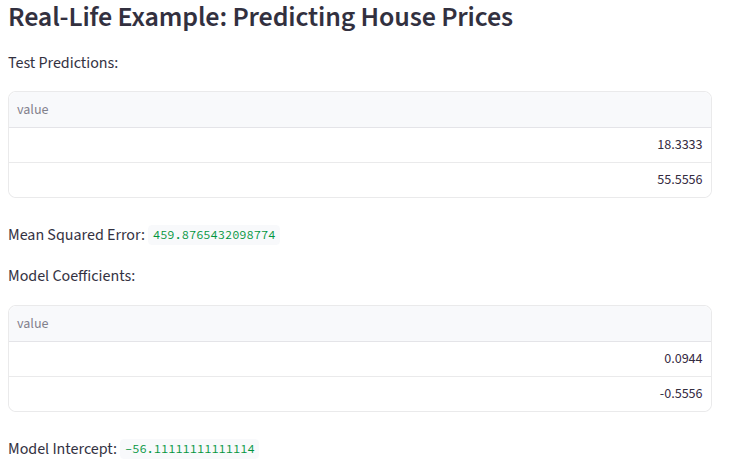
mse = mean_squared_error(y_test, pred)
st.subheader("Real-Life Example: Predicting House Prices")
st.write("Test Predictions:", pred)
st.write("Mean Squared Error:", mse)
st.write("Model Coefficients:", model.coef_)
st.write("Model Intercept:", model.intercept_)Output:
6. TensorFlow
Category: Deep Learning & AI
Machine learning and artificial intelligence are transforming the way we interact with technology. If you are a Python developer wanting to build AI models, one of the first libraries you should learn—often mentioned among the Top Python Libraries—is TensorFlow. Created by Google, TensorFlow is an open-source library that helps you design, train, and deploy machine learning models efficiently, making it a key part of the Top Python Libraries ecosystem for AI and deep learning.
Whether you want to build image recognition systems, predictive models, or neural networks, TensorFlow provides a simple yet powerful platform to do it all and is considered one of the Top Python Libraries for deep learning. Thanks to its rich ecosystem and flexibility, TensorFlow — along with other Top Python Libraries — makes it easier to take AI projects from prototype to production.
Why TensorFlow is Popular
- Flexibility: You can build models for research, production, and mobile deployment.
- High Performance: It uses efficient computation graphs and can run on CPU, GPU, or TPU.
- Large Community: Extensive tutorials, documentation, and support.
- Integrations: Works well with Keras, NumPy, Pandas, and visualization tools like Matplotlib.
TensorFlow’s modular design lets beginners quickly start with pre-built models while also providing advanced users the flexibility to customize. Its versatility is one reason it’s included among the Top Python Libraries for AI development. As part of the broader ecosystem of Top Python Libraries, TensorFlow supports everything from rapid prototyping to highly advanced deep-learning architectures.
Key Functionalities:
- Neural Networks: flexible architecture for building and training deep learning models.
- Tensorboard: A visualization toolkit to track model metrics like loss and accuracy.
- Deployment: Models can be deployed on CPUs, GPUs, TPUs, mobile devices, and even in the browser (TensorFlow.js).
- Keras Integration: Uses Keras as a high-level API to make building models easier for beginners.
Code snippets that demonstrate Line charts:
import tensorflow as tf
import numpy as np
# Sample data: area (sq.ft) vs price (in lakh)
X = np.array([800, 1200, 1500, 1800, 2000, 2200], dtype=float)
y = np.array([45, 70, 85, 110, 130, 150], dtype=float)
# Build a simple linear model
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=1, input_shape=[1])
])
# Compile the model
model.compile(optimizer='adam', loss='mean_squared_error')
# Train the model
model.fit(X, y, epochs=500, verbose=0)
# Make predictions
area_test = np.array([1600, 2500], dtype=float)
predictions = model.predict(area_test)
st.title("Tensorflow")
print("Predicted Prices:", predictions.flatten())Output :
Predicted Prices: [49.57787 77.29605]
7. BeautifulSoup (bs4)
Category: Web Scraping
In today’s digital world, information is everywhere on the web. If you want to extract data from websites automatically, Python provides a powerful and easy-to-use library called BeautifulSoup — one of the Top Python Libraries for web scraping. It allows developers to scrape web pages, parse HTML, and extract the content they need for analysis or automation. As part of the broader ecosystem of Top Python Libraries, BeautifulSoup makes data extraction simple, flexible, and highly efficient.
Whether you are collecting product prices, news headlines, or stock data, BeautifulSoup makes it simple to get structured data from unstructured HTML.
Why Use BeautifulSoup?
- Easy to Learn: Beginner-friendly syntax and clear documentation.
- Flexible Parsing: Supports HTML and XML files.
- Integration: Works well with requests, Pandas, and other Python libraries.
- Automation: Helps in creating scripts to extract data from multiple web pages.
Key Functionalities:
- HTML Parsing: Navigates the parse tree (the HTML structure) to locate specific tags.
- Search Methods: Finds elements by ID, class, CSS selector, or tag name using methods like .find() and .find_all().
- Broken HTML Handling: It is famous for being able to parse poorly written or “broken” HTML code without crashing.
- Data Extraction: Easily extracts text, links (hrefs), and image sources from web pages.
Installing BeautifulSoup
You can install BeautifulSoup using pip:
pip install beautifulsoup4
pip install lxmlbeautifulsoup4: The core library for parsing HTML.
lxml: A fast parser recommended for performance.Real-Life Example: Scraping News Headlines
Let’s scrape a few headlines from a sample HTML page.
Python Code
import requests
from bs4 import BeautifulSoup
# URL to scrape
url = "https://example.com/news"
# Fetch the page content
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
html_content = response.text
# Parse the HTML content
soup = BeautifulSoup(html_content, "lxml")
# Extract all headlines (assuming <h2> tags)
headlines = soup.find_all("h2")
# Print headlines
print("News Headlines:")
for i, headline in enumerate(headlines, start=1):
print(f"{i}. {headline.get_text(strip=True)}")
else:
print("Failed to retrieve the webpage.")
Output:
News Headlines:
1. Python 4.0 Features Revealed
2. New AI Model Predicts Stock Prices
3. Web Scraping Trends in 2025
Top Python Libraries with Official Links
Here’s a cleaner version of your Python roadmap with more suitable topics and only official-site links 👇
1. Introduction
- Python Official: https://docs.python.org/3/tutorial/appetite.html
- W3Schools – Intro: https://www.w3schools.com/python/python_intro.asp
2. Getting Started
- Installing Python: https://docs.python.org/3/tutorial/interpreter.html
- Python Syntax (W3): https://www.w3schools.com/python/python_syntax.asp
- Python Comments: https://www.w3schools.com/python/python_comments.asp
- Running Python Files: https://docs.python.org/3/tutorial/interpreter.html
3. Python Basics
- Variables: https://www.w3schools.com/python/python_variables.asp
- Data Types: https://www.w3schools.com/python/python_datatypes.asp
- Type Casting: https://www.w3schools.com/python/python_casting.asp
- Input & Output: https://docs.python.org/3/library/functions.html#print
- Indentation: https://www.w3schools.com/python/python_syntax.asp
4. Operators
- Arithmetic Operators: https://www.w3schools.com/python/python_operators.asp
- Assignment Operators: https://www.w3schools.com/python/python_operators.asp
- Logical Operators: https://www.w3schools.com/python/python_operators.asp
- Comparison Operators: https://www.w3schools.com/python/python_operators.asp
- Identity & Membership Operators: https://www.w3schools.com/python/python_operators.asp
5. Control Flow
- If/Else Statements: https://www.w3schools.com/python/python_conditions.asp
- For Loops: https://www.w3schools.com/python/python_for_loops.asp
- While Loops: https://www.w3schools.com/python/python_while_loops.asp
- Break/Continue: https://www.w3schools.com/python/python_break.asp
- Match Case (Python 3.10+): https://docs.python.org/3/tutorial/controlflow.html#match-statements
6. Data Structures
Lists
- Lists: https://www.w3schools.com/python/python_lists.asp
- List Methods: https://www.w3schools.com/python/python_lists_methods.asp
- List Comprehension: https://www.w3schools.com/python/python_lists_comprehension.asp
Tuples
Sets
- Sets: https://www.w3schools.com/python/python_sets.asp
- Set Methods: https://www.w3schools.com/python/python_sets_methods.asp
Dictionaries
- Dictionaries: https://www.w3schools.com/python/python_dictionaries.asp
- Dictionary Methods: https://www.w3schools.com/python/python_dictionaries_methods.asp
7. Strings
- Strings: https://www.w3schools.com/python/python_strings.asp
- String Methods: https://www.w3schools.com/python/python_strings_methods.asp
- f-Strings: https://docs.python.org/3/tutorial/inputoutput.html#formatted-string-literals
8. Functions
- Defining Functions: https://www.w3schools.com/python/python_functions.asp
- Lambda Functions: https://www.w3schools.com/python/python_lambda.asp
- Recursion: https://docs.python.org/3/tutorial/controlflow.html#recursive-functions
- Args & Kwargs: https://www.w3schools.com/python/python_functions.asp
9. Modules & Packages
- Modules: https://www.w3schools.com/python/python_modules.asp
- Packages: https://docs.python.org/3/tutorial/modules.html#packages
- Pip & Installing Packages: https://www.w3schools.com/python/python_pip.asp
- Virtual Environments: https://docs.python.org/3/tutorial/venv.html
10. File Handling
- Read Files: https://www.w3schools.com/python/python_file_open.asp
- Write Files: https://www.w3schools.com/python/python_file_write.asp
- JSON Handling: https://www.w3schools.com/python/python_json.asp
11. Errors & Exceptions
- Errors: https://docs.python.org/3/tutorial/errors.html
- Try/Except: https://www.w3schools.com/python/python_try_except.asp
- Raising Exceptions: https://docs.python.org/3/tutorial/errors.html#raising-exceptions
12. Object-Oriented Programming (OOP)
- Classes & Objects: https://www.w3schools.com/python/python_classes.asp
- Inheritance: https://www.w3schools.com/python/python_inheritance.asp
- Magic Methods: https://docs.python.org/3/reference/datamodel.html#special-method-names
13. Advanced Concepts
- Iterators: https://www.w3schools.com/python/python_iterators.asp
- Generators: https://www.w3schools.com/python/python_generators.asp
- Decorators: https://docs.python.org/3/tutorial/classes.html#decorators
- Closures: https://docs.python.org/3/reference/executionmodel.html#naming-and-binding
14. Working with Libraries
- NumPy: https://numpy.org/learn/
- Pandas: https://pandas.pydata.org/docs/getting_started/index.html
- Matplotlib: https://matplotlib.org/stable/tutorials/index.html
- Requests (HTTP): https://requests.readthedocs.io/en/latest/
15. Python Automation
- OS Module: https://docs.python.org/3/library/os.html
- Subprocess: https://docs.python.org/3/library/subprocess.html
- Scheduling: https://pypi.org/project/schedule/
16. Python for Web Development
- Flask: https://flask.palletsprojects.com/en/stable/
- Django: https://docs.djangoproject.com/en/stable/
17. Python for Data Science & Machine Learning
- Scikit-learn Intro: https://scikit-learn.org/stable/tutorial/basic/tutorial.html
- Data Cleaning: https://pandas.pydata.org/docs/
- Visualization: https://matplotlib.org/stable/users/index.html
18. Testing & Debugging
- Debugging: https://docs.python.org/3/library/pdb.html
- Unit Testing: https://docs.python.org/3/library/unittest.html
19. Databases
- SQLite: https://docs.python.org/3/library/sqlite3.html
- SQLAlchemy: https://docs.sqlalchemy.org/en/latest/tutorial/
20. Projects (Step-by-Step Guides)
Pandas Data Project: https://pandas.pydata.org/docs/getting_started/
Build a Calculator: https://www.w3schools.com/python/python_examples.asp
To-Do App (Flask): https://flask.palletsprojects.com/en/stable/tutorial/
Weather API App: https://requests.readthedocs.io/en/latest/
Conclusion
Python’s vast library ecosystem makes it the ultimate choice for developers, data scientists, and AI enthusiasts. Libraries like Pandas, NumPy, Scikit-learn, TensorFlow, Flask, and BeautifulSoup empower you to handle data analysis, machine learning, web development, and automation with ease.
If you’re new to Python, make sure to also check out our Python Programming for Beginners: The Ultimate Guide to Start Coding in 2025 and our detailed tutorial Python Syntax and Variables: The Complete Beginner’s Guide with Real-World Examples for a solid foundation before diving into these Top Python Libraries.



