


Data Structures and MySQL Stores Data aren’t just for computer science majors.
They’re the silent architects behind every fast, scalable, and powerful piece of software you’ve ever used.
Still think they’re “too theoretical”?
Let me reframe that for you.
If you’ve ever:
• Waited for a search bar to suggest your query in milliseconds
• Wondered how Instagram loads thousands of posts instantly
- Or built an app that slows to a crawl when scaled…
The Core Idea — What are Data Structures?
At a fundamental level, data structures are techniques used to organize and manage data in computer memory, enabling efficient access, updates, and processing, especially in how MySQL stores data.
Why Data Structures Matter in How MySQL Stores Data
✅ Speed & Performance
They make everyday operations like searching, inserting, and deleting data significantly faster.
✅ Efficient Resource Management
Proper data structures ensure smarter use of memory and computing power, reducing waste and improving scalability, which is crucial for how MySQL stores data efficiently.
✅ Smarter Problem Solving
Each challenge has an ideal structure. Choosing the right one helps simplify logic and improve maintainability, especially in the way MySQL stores data.
Two Pillars of Data Structures
When it comes to organizing data, especially in databases, everything starts with how elements are arranged in memory, and how efficiently MySQL stores data plays a crucial role in this process. This forms the foundation for two key categories:
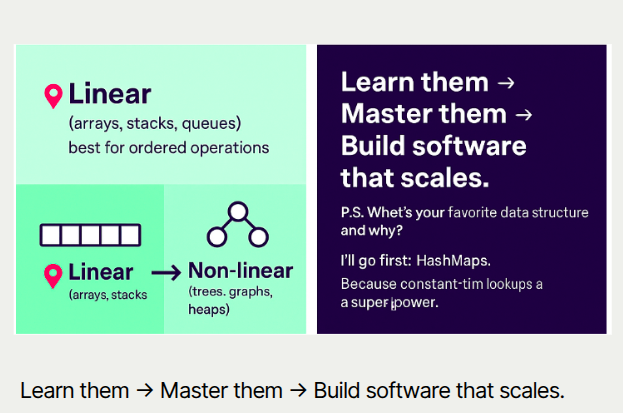
🔹 Linear Structures
Data is arranged in a straight sequence — one item after another, like links in a chain.
Examples: Arrays, Linked Lists, Stacks, Queues
Best for: Scenarios where order matters and operations follow a predictable path.
🔹 Non-Linear Structures
Data forms branches or networks — elements connect in multiple directions, not just a straight line.
Examples: Trees, Graphs, Heaps, Tries
Best for: Representing hierarchies, relationships, or multiple paths between items. Perfect for complexity and relationships.
Linear Data Structures — Organized, One After The Other
Linear data structures store elements in a single, continuous sequence, making them predictable and efficient for many common tasks, especially in the way MySQL stores data. Let’s break them down:
🔸 1. Array — The Memory Grid
What it is: A block of memory where elements live side by side in contiguous slots.
Types:
Static Array: Fixed size at the time of creation.
Dynamic Array: Resizes as needed (like ArrayList in Java or std::vector in C++).
Why it’s useful: Instantly access any item by its index — in O(1) time.
Common Uses: Lookup tables, storing fixed-size datasets.

2. Linked List — The Flexible Chain
What it is: A sequence of nodes where each node contains data and a reference (or “link”) to the next one.
Types:
Singly Linked: Points to the next node.

Why it’s useful: O(1) insertion/deletion if you know the node’s position.
Common Uses: Building stacks, queues, and dynamic memory models.
Stack — The LIFO Powerhouse in Programming
A Stack is a data structure that operates on the Last-In, First-Out (LIFO) principle — just like stacking plates: the last plate you place on top is the first one you remove.
How it Works
push() → Adds an item to the top
pop() → Removes the item from the top

Where It’s Used
- Function call tracking in programming languages
- Undo/Redo operations in editors
- Syntax parsing in compilers
Queue
In the world of data structures, a Queue is a powerful concept that mirrors real-life lines — like waiting for a movie ticket. It works on a First In, First Out (FIFO) principle. 🚶♂️➡️🚶♀️➡️🚶
What is a Queue?
A Queue is a linear structure where elements are added at the rear and removed from the front.
🛠 Key Operations:
- enqueue() → Add item at the end
- dequeue() → Remove item from the front
- peek() → Check the front item
- isEmpty() → Check if queue is empty
Real-life Use Cases:
- CPU job scheduling
- Web server request handling
- Breadth-First Search in graphs
- Messaging systems like Kafka or RabbitMQ
🔄 Types of Queues:
- Simple Queue — Standard FIFO
- Circular Queue — Optimized for fixed-size arrays
- Priority Queue — Elements with higher priority dequeued first
- Deque — Insertion/removal from both ends
“A queue is more than just a line — it’s a disciplined flow of tasks.”
class Queue {
constructor() {
this.items = [];
}
enqueue(element) {
this.items.push(element);
}
dequeue() {
return this.items.shift();
}
peek() {
return this.items[0];
}
isEmpty() {
return this.items.length === 0;
}
}
Non-Linear Structures:
When managing data in databases like MySQL, not all structures are created equal. While linear structures (like arrays and linked lists) have their place, non-linear data structures truly shine in complex, hierarchical, or relational scenarios where MySQL stores data efficiently.
Let’s explore what non-linear structures are — and how MySQL uses them behind the scenes.
What Are Non-Linear Data Structures?
Non-linear structures don’t store data in a straight line. Instead, elements are hierarchically or relationally connected — a structure that aligns with how MySQL stores data for more dynamic and efficient handling.
Examples:
- Trees (Binary Trees, B+ Trees, Tries)
- Graphs
- Heaps
🔍 Real-Life Example: MySQL Table as a Tree
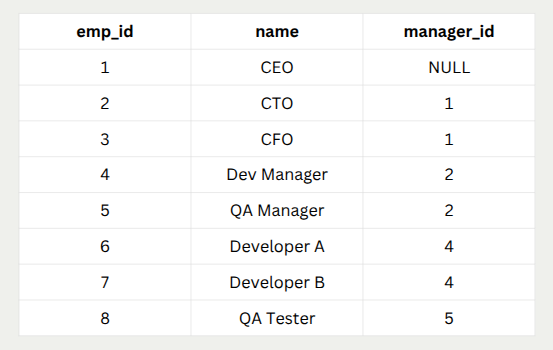
Imagine we’re storing an employee hierarchy in a table:
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
name VARCHAR(100),
manager_id IN
);
Sample Data:
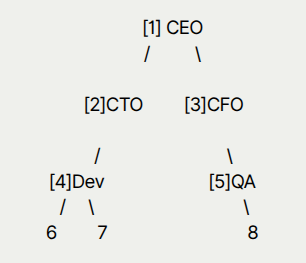
Tree View (Org Chart):
Using MySQL 8+ recursive CTEs:
WITH RECURSIVE emp_hierarchy AS (
SELECT * FROM employees WHERE emp_id = 2
UNION ALL
SELECT e.* FROM employees e
JOIN emp_hierarchy eh ON e.manager_id = eh.emp_id
)
SELECT * FROM emp_hierarchy;
Perfect for traversing and analyzing a full management chain.
Why B+ Trees for Primary Keys in MySQL?
MySQL’s InnoDB engine uses B+ Trees by default for indexes and primary keys. Here’s why:

⚖️ Which Non-Linear Structure Fits Which Use Case?
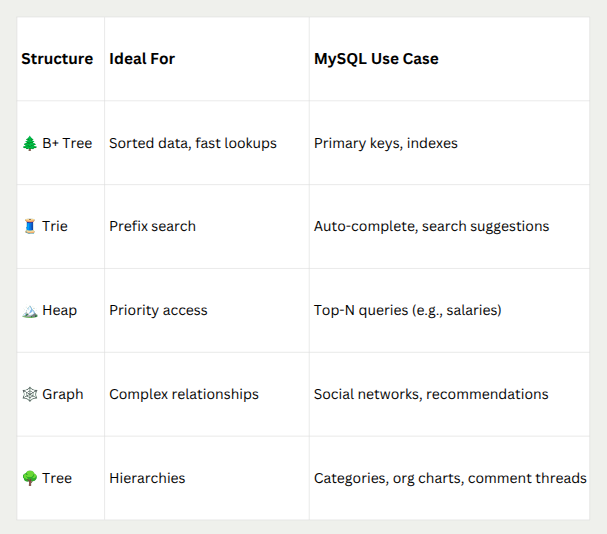
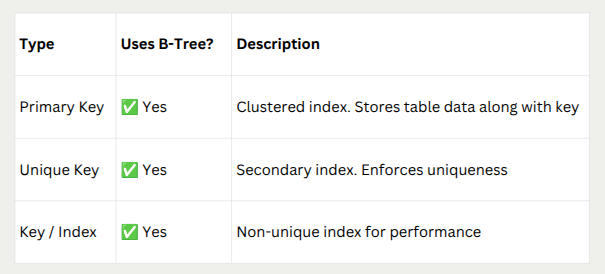
Are primary keys, unique keys, and regular keys all stored using a B-Tree when MySQL stores data?
Primary Key:
✅ Stored in a B-Tree
In InnoDB (MySQL’s default engine), the primary key is clustered, meaning MySQL stores data in the B-Tree along with the primary key.
Each row in the table is physically stored in order based on the primary key.
Unique Key:
✅ Stored in a B-Tree
- A unique index ensures that the values in the indexed column(s) are unique.
- It uses a B-tree structure like a normal index.
- If it’s not the primary key, it’s stored as a secondary index and still uses B-Tree.
Key / Index (Non-unique)
✅ Stored in a B-Tree
- Any index created using INDEX or KEY also uses a B-Tree by default.
- Used to speed up search queries, even if the values are not unique.
Summary Table:
✅ B-Tree Advantages:
- Fast search, insert, and delete operations.
- Supports range queries, like BETWEEN, >, <, etc.
- Optimized for disk I/O
❌ Hash Tables are good for lookups but cannot do range scans.
❌ AVL/RBT are better for memory but less efficient on disk.
Final Thoughts
- Using the right data structure can dramatically improve how we store, query, and visualize data, especially in large, relational databases where MySQL stores data efficiently.
- Understanding structures like B+ Trees and Trees is crucial for building optimized and scalable applications.



